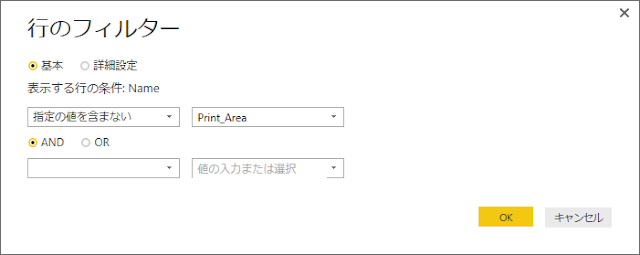
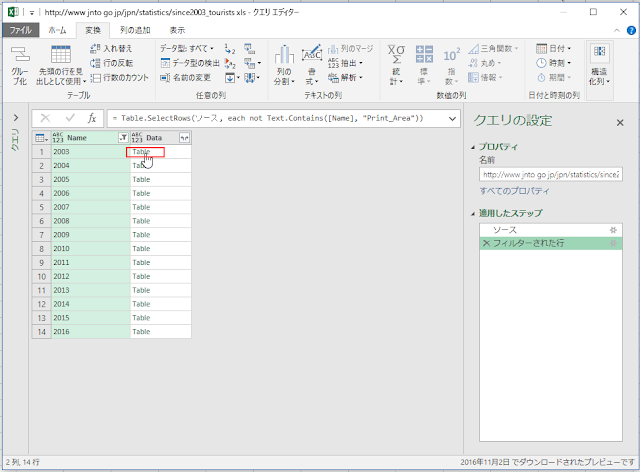
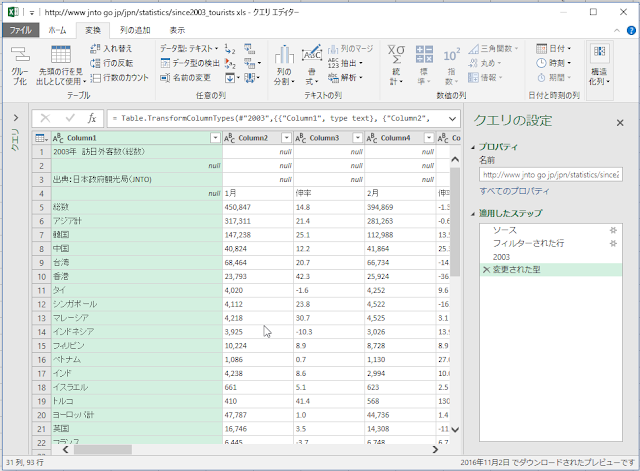
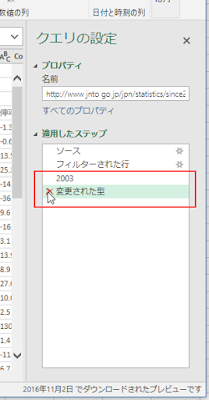
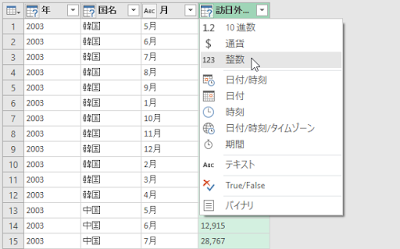
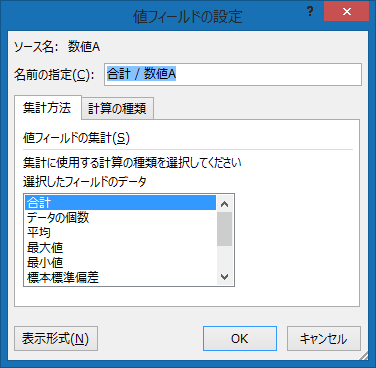
以下のようなケースではどうすればいいでしょうか?という質問を Office TANAKA セミナーでいただきました。
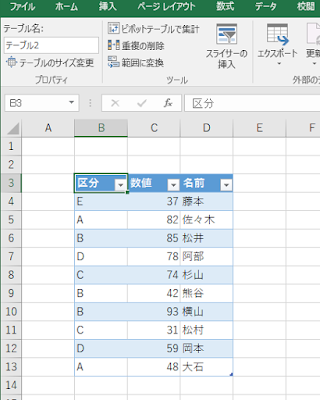
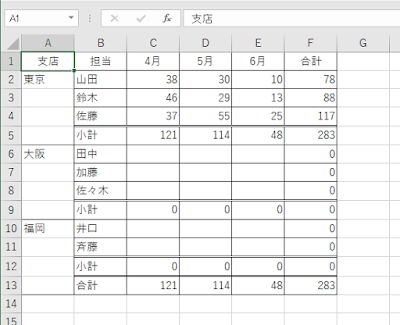
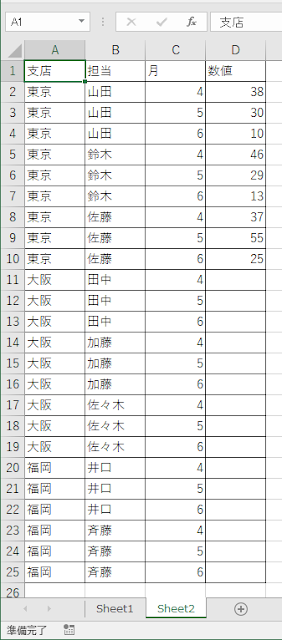
ものすごく簡略化したケースで検討しますが、たとえば、アンケート結果の集計のようなもので、評価項目はA, B, C, D, Eまであるんだけど、Eを付けた人はいない、というデータがあったとします。
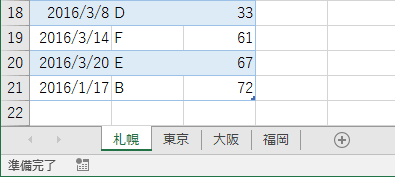
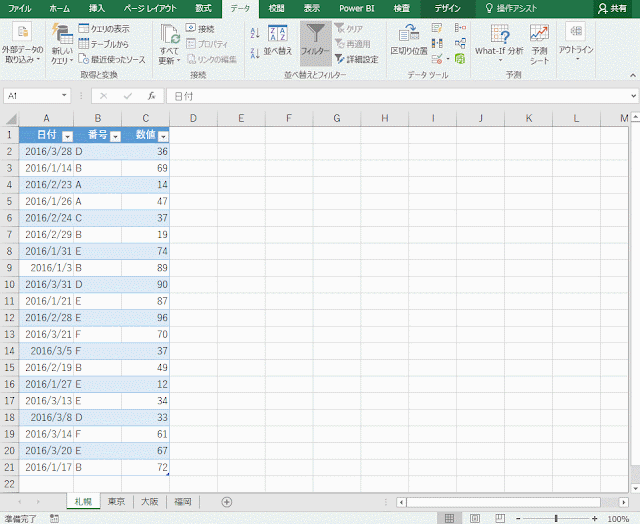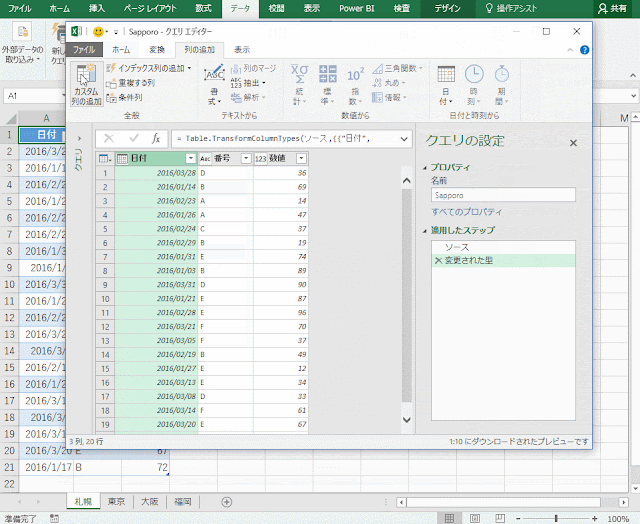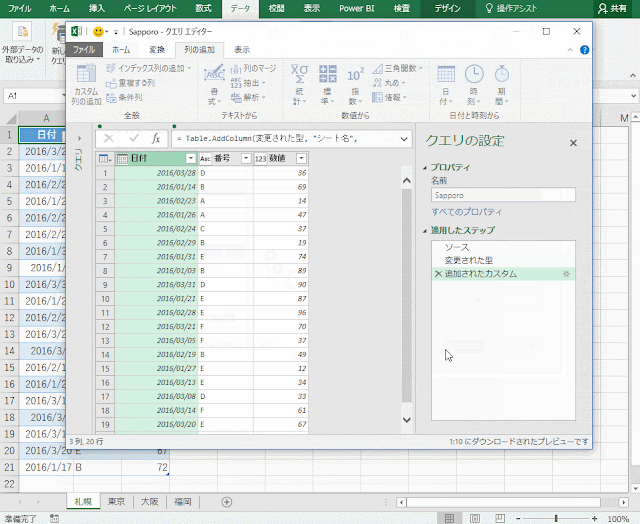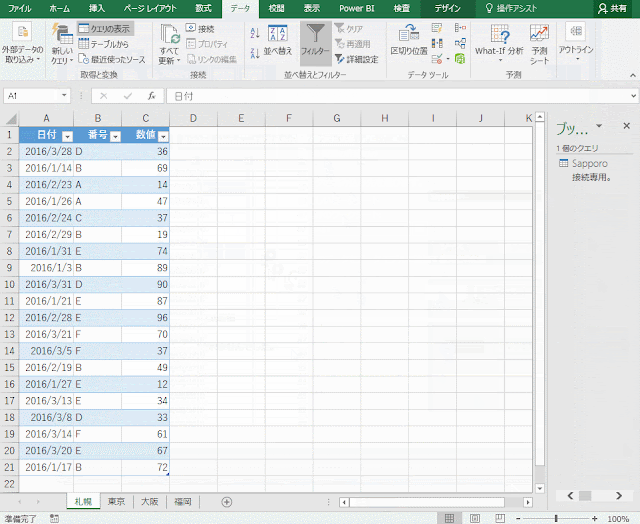
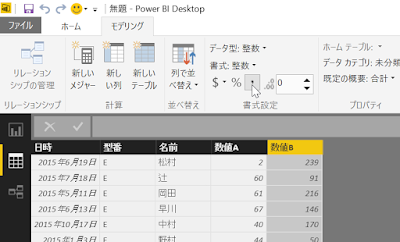
こんな感じのデータを想定します。
![]()
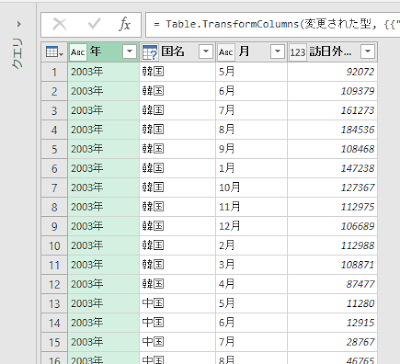
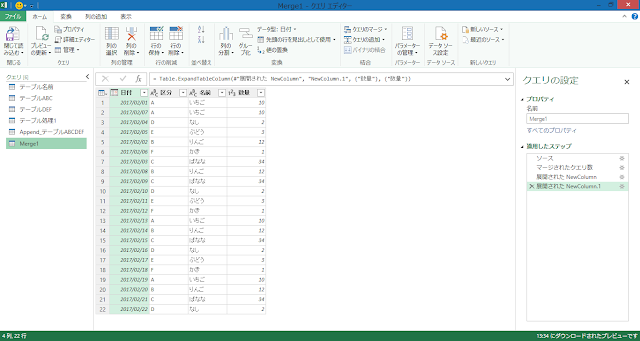
このテーブルからピボットテーブルを作ると以下のようになります。
![]()
元データのテーブルには評価で「E」というデータはありません。この元データからわかることは、AからDまでは評価のデータとして存在するが、Eもしくはそれ以降のデータがあるかどうかは判断が付きませんから、当然といえば当然です。
とはいえ、操作している側としては、Eまで評価があり、それを含めて以下のようなピボットテーブルが欲しい、と考えるのは当然ですよね。
![]()
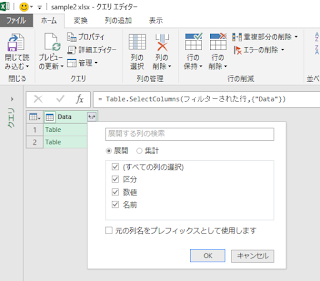
出力用で、A~Eをあらかじめ用意し、GETPIVOTDATA関数とIFERROR関数を使って抜き出し、ゼロの対応が可能です。もちろん、簡略化しているので、この程度のサンプルならピボットを使うまでのことはなく、COUNTIFで十分だろう、というのはご容赦ください(笑)。
あくまで、ピボットテーブルの機能で対応しようとすると、評価の行ラベルが AからEまであることをピボットテーブルに伝えなければなりません。
実データを元にしてラベルを作る(=重複しないデータを作ってラベルを作っているんです)のではなく、たとえて言うなら、入力規則の元データとなるリストを元にラベルを作り、そのリストの項目からそれぞれの項目がいくつ選択されたのかを集計したい、といえます。
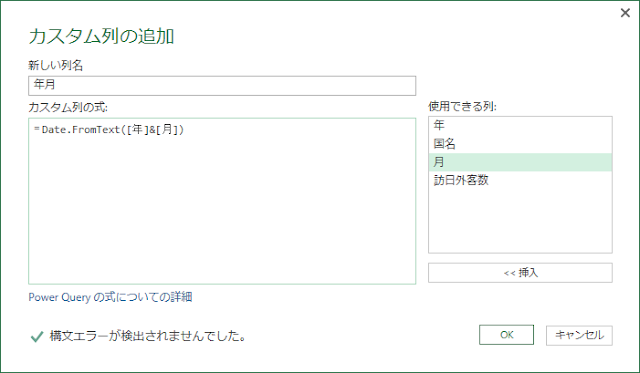
ということで、入力規則のリストに相当する評価テーブルのようなものを用意します。
![]()
この評価テーブルのAからEは、アンケート結果テーブルのAからEとの間でリレーションシップを組むことができます。アンケート結果テーブルの A とは「とても良い」ですよ、ということです。ワークシート関数では VLOOKUP関数を使って、「とても良い」や「良い」を参照しますよね。
このリレーションシップ、Excel 2013以降の標準機能です。
もっとも簡単な方法は、ピボットテーブル作成時に「複数のテーブルを使う」オプションを指定し、リレーションシップを自動検出させる方法です。シンプルなテーブルであれば、これで十分です。
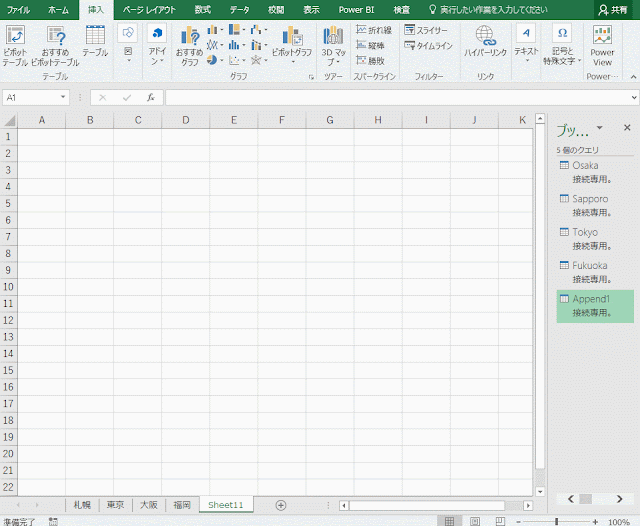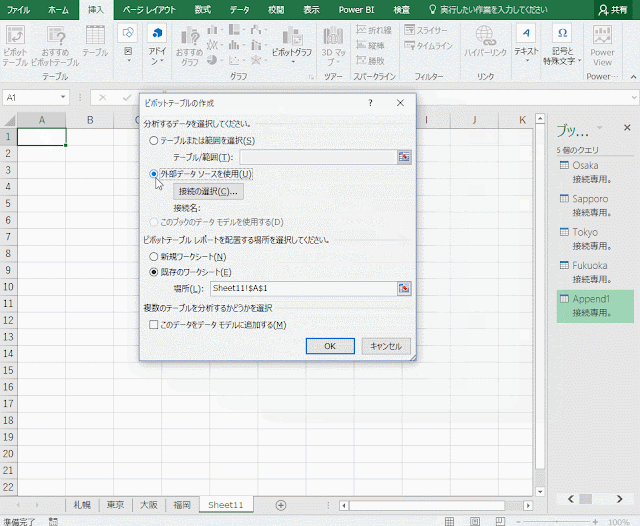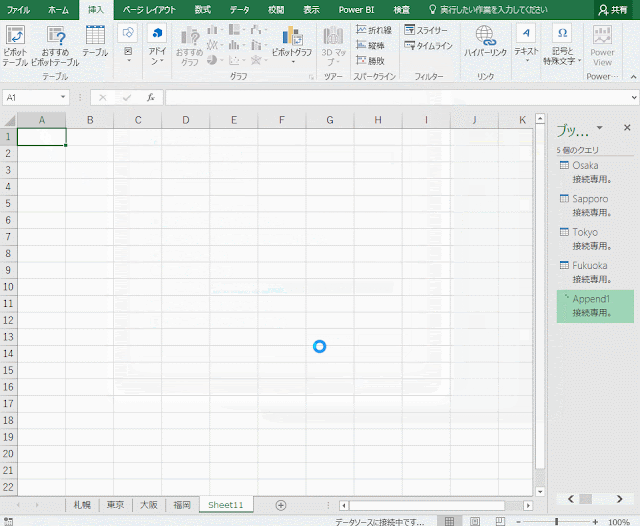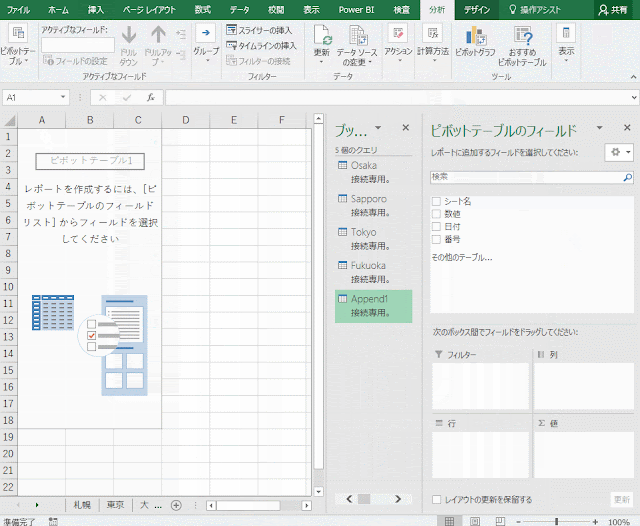
アンケート結果のテーブルにアクティブセルを置いて、ピボットテーブルを作成します。その時、[複数のテーブルを分析する] の利用のオプションである [このデータをデータモデルに追加する] をオンにします。
![]()
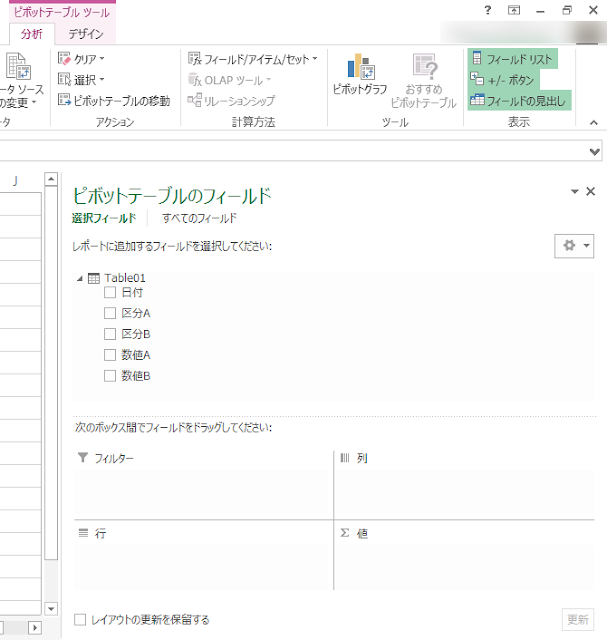
フィールド リスト ウィンドウで、すべてのテーブルを表示するため [すべて] タブを選択し、AからEの評価を含む [評価テーブル] の [評価] を行ラベルとしてドロップします。
![]()
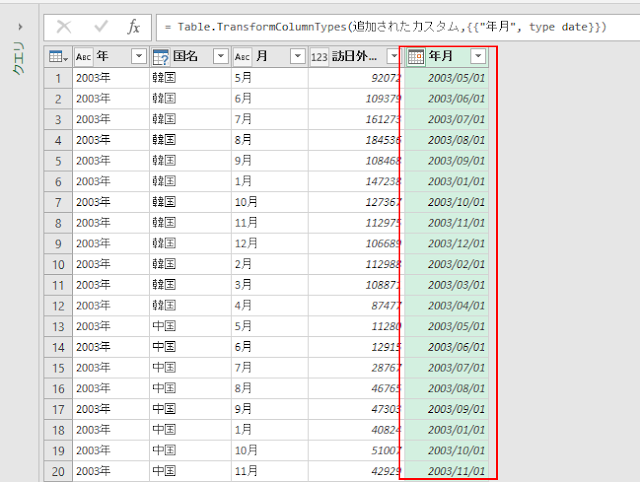
これで、AからEの行ラベルが表示された空のピボットテーブルが作成されます。
![]()
次に、アンケート結果の実データがある [アンケート結果] テーブルから個数を数えるために [名前]を[値エリア]にドロップします。すると、ウィンドウ上部にリレーションシップの自動検出ボタンが表示されます。
今回は評価 - 評価 でシンプルな例なので、自動検出を使います。もちろん、[作成] で手動で設定してもかまいません。
![]()
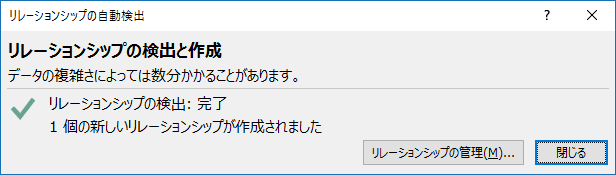
問題がなければ、以下のようなダイアログが表示されます。
![]()
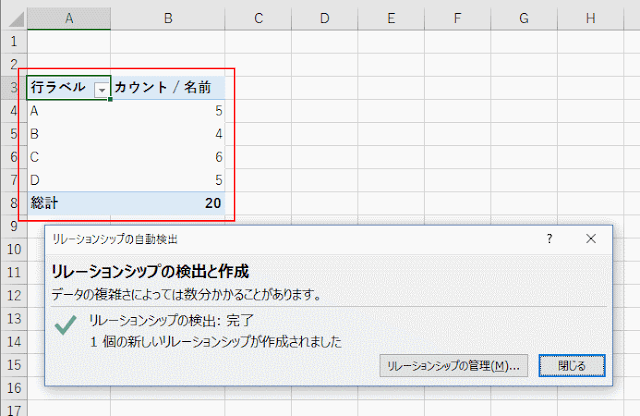
ところが、この状態だと、あの空だったピボットテーブルは、期待した E の行が消えたものになります。
![]()
ここで、慌てず、ピボットテーブルのオプションの確認です。
少なくとも、データが入る前は、[E] が表示されていました。こういう場合は「データの無いアイテム(行・列)に関連するオプション」があるんじゃないか、とあたりをつけて探します。
実はこれに関連するオプション、普通に Excel のワークシートのデータを扱っている限りだと、使える状況になったことを見た人は少ないと思います。
![]()
これは、ピボットテーブルをやっていると良く目にする「OLAPデータ ソース」が元データだった場合に有効になるオプションでした。
オンライン分析処理の概要
https://support.office.com/ja-jp/article/15d2cdde-f70b-4277-b009-ed732b75fdd6
Excelのデータ モデル オブジェクトは、OLAPデータ ソースのキューブファイルと同じ振る舞いをするようです。事実、データ モデルを接続のプロパティでみたのが以下です。
![]()
ということで、今まで使えなかった、この「データのないアイテムを行・列に表示する」をオンにします。
![]()
すると、以下のようになります。
![]()
Eが表示されました。
しかし、空欄です。できれば 0 を表示したいところです。
これもピボットテーブルのオプション [空白セルに表示する値] で 0 を指定できます。
![]()
これらの設定をすると、ピボットテーブルが以下のようになります。
![]()
ピボットテーブルのような「機能」は、どんなものがオプションにあるか知らないと実現できないことが多いです。その意味では「機能」も習得するのが簡単ではありませんよね。
ものすごく簡略化したケースで検討しますが、たとえば、アンケート結果の集計のようなもので、評価項目はA, B, C, D, Eまであるんだけど、Eを付けた人はいない、というデータがあったとします。
こんな感じのデータを想定します。

このテーブルからピボットテーブルを作ると以下のようになります。
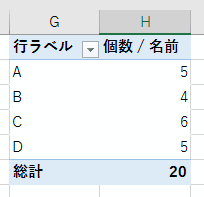
元データのテーブルには評価で「E」というデータはありません。この元データからわかることは、AからDまでは評価のデータとして存在するが、Eもしくはそれ以降のデータがあるかどうかは判断が付きませんから、当然といえば当然です。
とはいえ、操作している側としては、Eまで評価があり、それを含めて以下のようなピボットテーブルが欲しい、と考えるのは当然ですよね。

出力用で、A~Eをあらかじめ用意し、GETPIVOTDATA関数とIFERROR関数を使って抜き出し、ゼロの対応が可能です。もちろん、簡略化しているので、この程度のサンプルならピボットを使うまでのことはなく、COUNTIFで十分だろう、というのはご容赦ください(笑)。
あくまで、ピボットテーブルの機能で対応しようとすると、評価の行ラベルが AからEまであることをピボットテーブルに伝えなければなりません。
実データを元にしてラベルを作る(=重複しないデータを作ってラベルを作っているんです)のではなく、たとえて言うなら、入力規則の元データとなるリストを元にラベルを作り、そのリストの項目からそれぞれの項目がいくつ選択されたのかを集計したい、といえます。
ということで、入力規則のリストに相当する評価テーブルのようなものを用意します。
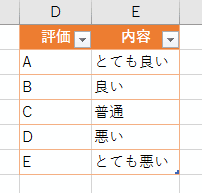
この評価テーブルのAからEは、アンケート結果テーブルのAからEとの間でリレーションシップを組むことができます。アンケート結果テーブルの A とは「とても良い」ですよ、ということです。ワークシート関数では VLOOKUP関数を使って、「とても良い」や「良い」を参照しますよね。
このリレーションシップ、Excel 2013以降の標準機能です。
もっとも簡単な方法は、ピボットテーブル作成時に「複数のテーブルを使う」オプションを指定し、リレーションシップを自動検出させる方法です。シンプルなテーブルであれば、これで十分です。
アンケート結果のテーブルにアクティブセルを置いて、ピボットテーブルを作成します。その時、[複数のテーブルを分析する] の利用のオプションである [このデータをデータモデルに追加する] をオンにします。
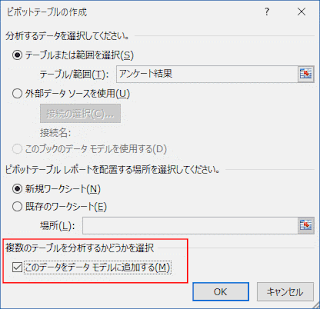
フィールド リスト ウィンドウで、すべてのテーブルを表示するため [すべて] タブを選択し、AからEの評価を含む [評価テーブル] の [評価] を行ラベルとしてドロップします。

これで、AからEの行ラベルが表示された空のピボットテーブルが作成されます。

次に、アンケート結果の実データがある [アンケート結果] テーブルから個数を数えるために [名前]を[値エリア]にドロップします。すると、ウィンドウ上部にリレーションシップの自動検出ボタンが表示されます。
今回は評価 - 評価 でシンプルな例なので、自動検出を使います。もちろん、[作成] で手動で設定してもかまいません。
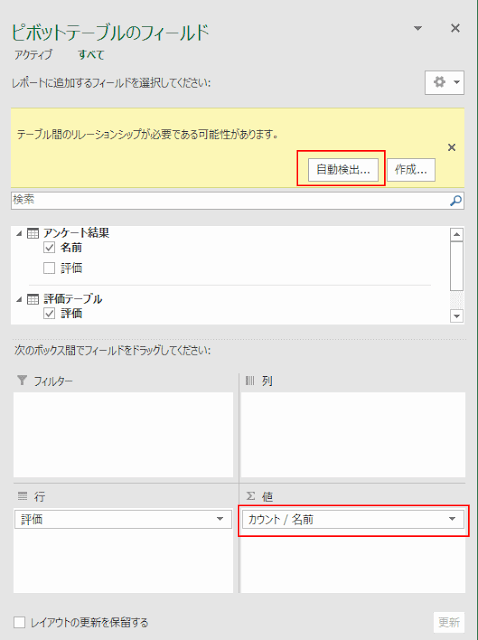
問題がなければ、以下のようなダイアログが表示されます。
ところが、この状態だと、あの空だったピボットテーブルは、期待した E の行が消えたものになります。
ここで、慌てず、ピボットテーブルのオプションの確認です。
少なくとも、データが入る前は、[E] が表示されていました。こういう場合は「データの無いアイテム(行・列)に関連するオプション」があるんじゃないか、とあたりをつけて探します。
実はこれに関連するオプション、普通に Excel のワークシートのデータを扱っている限りだと、使える状況になったことを見た人は少ないと思います。
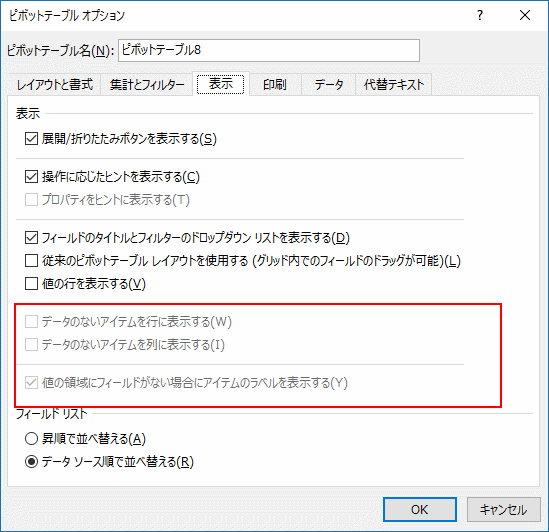
これは、ピボットテーブルをやっていると良く目にする「OLAPデータ ソース」が元データだった場合に有効になるオプションでした。
オンライン分析処理の概要
https://support.office.com/ja-jp/article/15d2cdde-f70b-4277-b009-ed732b75fdd6
Excelのデータ モデル オブジェクトは、OLAPデータ ソースのキューブファイルと同じ振る舞いをするようです。事実、データ モデルを接続のプロパティでみたのが以下です。

ということで、今まで使えなかった、この「データのないアイテムを行・列に表示する」をオンにします。

すると、以下のようになります。

Eが表示されました。
しかし、空欄です。できれば 0 を表示したいところです。
これもピボットテーブルのオプション [空白セルに表示する値] で 0 を指定できます。

これらの設定をすると、ピボットテーブルが以下のようになります。

ピボットテーブルのような「機能」は、どんなものがオプションにあるか知らないと実現できないことが多いです。その意味では「機能」も習得するのが簡単ではありませんよね。